Adding Composite Entities to Rasa NLU
Composite entities are tremendously useful when working with complex queries that contain more than one piece of information. At Dialogue Technologies we have implemented composite entities as a Rasa NLU component that can be dropped into any existing pipeline without having to rewrite training examples. We use this feature in our Dialogue Engine, a platform for conversational commerce. The component is freely available on Github.
What are composite entities (and why are they useful)?
Natural language processing tools like Rasa NLU parse sentences into structured data. Consider a sentence like
I am looking for a red shirt with stripes and checkered blue shoes.
The data extracted by Rasa NLU might look like
{
"intent": "search_product",
"entities": [
{
"entity": "color",
"value": "red"
},
{
"entity": "product",
"value": "shirt"
},
{
"entity": "pattern",
"value": "striped"
},
{
"entity": "pattern",
"value": "checkered"
},
{
"entity": "color",
"value": "blue"
},
{
"entity": "product",
"value": "shoe"
}
]
}
Transforming the input query into intents and entities allows us to act upon the contained information. However, it’s hard to infer the user’s intention because the parsed entities lose their context. This becomes obvious for the two subsequent “pattern” entities. The user might be looking for a striped and checkered red shirt, or striped and checkered blue shoes, or a striped red shirt and checkered blue shoes.
Composite entities act as containers for other entities. By using composites, base entities can be grouped in logical units. Ideally, we would like Rasa NLU to return something similar to
{
"intent": "search_product",
"entities": [
{
"entity": "product_with_attributes",
"contained_entities": [
{
"entity": "color",
"value": "red"
},
{
"entity": "product",
"value": "shirt"
},
{
"entity": "pattern",
"value": "striped"
}
]
},
{
"entity": "product_with_attributes",
"contained_entities": [
{
"entity": "pattern",
"value": "checkered"
},
{
"entity": "color",
"value": "blue"
},
{
"entity": "product",
"value": "shoe"
}
]
}
]
}
Here we can see immediately which entities belong together.
Choosing the right implementation
There are two possible approaches when implementing composite entities. The first approach is to treat composites as “first-class entities” and to split them after extraction. The second approach is to combine extracted entities based on pre-defined patterns.
Approach one has three major drawbacks:
- The training examples have to be altered. In the example above, one would have to mark “red shirt with stripes” and “checkered blue shoes” as entities in the “common_examples” section of the train file.
- To split these composite entities into base entities, one basically has to perform another round of NLP. It’s still necessary to parse the composite entity to find the contained entities like “color: red” and “pattern: striped”.
- Due to point 2, other entity extractors cannot be leveraged. One might want to use the duckling extractor to parse the amount and delivery time of a request like “five pizza’s at 6pm”. This is not possible if the whole phrase is marked as a single composite entity.
For these reasons, we’ve opted to go with a pattern based approach. The training examples don’t have to be altered at all, the only necessary change is adding pattern definitions to the train file:
"composite_entities": [
{
"name": "product_with_attributes",
"patterns": [
"@color @product with @pattern",
"@pattern @color @product"
]
}
],
"common_examples": [
...
]
Entities are marked by using the “@” prefix. The entity names refer to the “entity” field in Rasa’s response message, not necessarily the entities from the common examples. This means that you can use any entity type in your patterns, even the ones from other components like duckling or custom components!
Using regexes for maximum flexibility
Pattern matching is implemented through regular expressions. In the original query sentence, all entity values are replaced by their entity type. The query sentence
I am looking for a red shirt with stripes and checkered blue shoes.
will be transformed into
I am looking for a @color @product with @pattern and @pattern @color @product.
All defined patterns are matched against this string. If a pattern matches, entities that are fully contained in the match will be placed inside a composite entity under the pattern’s name.
Using regular expressions offers a lot of flexibility in what patterns can match on. For example, it’s possible to define a pattern like
"composite_entities": [
{
"name": "product_with_attributes",
"patterns": [
"(?:@pattern\\s+)?(?:@color\\s+)?@product(?:\\s+with @[A-Z,a-z]+)?"
]
}
]
which produces two matches in the example query:
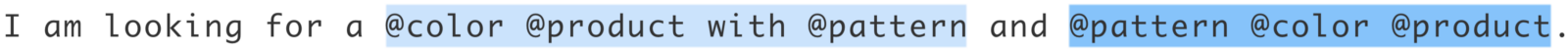
Both matches fully contain three entities, therefore two distinct composite entities will be created containing the respective base entities.
Another simple example could be a pattern that finds negations:
"composite_entities": [
{
"name": "excluded_entity",
"patterns": [
"without @[A-Z,a-z]+"
]
}
]
This pattern will match any entity that is preceded by the word “without” and therefore mark entities that should be excluded.
There are countless possibilities of how to use pattern based composite entities in your pipeline. Not everyone requires them, but we surely missed composites when we switched from Dialogflow to Rasa NLU.